基于Docker的Hadoop和Spark环境搭建
2023年8月21日
本文主要介绍了如何在docker中快速搭建Hadoop和Spark环境。如果想入门大数据,那么一个Docker环境下的大数据平台是最佳学习方式。
环境
环境:MacOS Ventura 13.5
机型:MacBook Pro (M1, 2021)
准备工作
Move hadoop-3.3.1-aarch64.tar.gz、jdk-8u301-linux-aarch64.tar.gz、scala-2.12.14.tgz、spark-3.2.1-bin-hadoop3.2.tgz and pyspark-3.4.1.tar.gz to resources folder
构建
build Dockerfile
点击显示代码
Dockerfile fileFROM ubuntu:20.04
LABEL maintainer="puppets"
WORKDIR /root
# install openssh-server, openjdk and wget
RUN apt-get update && apt-get install -y openssh-server wget
RUN apt install python-is-python3
RUN apt install python3-pip -y
RUN apt install -y mysql-server
ADD resources/hadoop-3.3.1-aarch64.tar.gz /usr/local/hadoop
ADD resources/jdk-8u301-linux-aarch64.tar.gz /usr/local/hadoop
ADD resources/scala-2.12.14.tgz /usr/local/hadoop
ADD resources/spark-3.2.1-bin-hadoop3.2.tgz /usr/local/hadoop
COPY resources/pyspark-3.4.1.tar.gz /usr/local/hadoop
COPY resources/apache-hive-3.1.3-bin.tar.gz /usr/local/hadoop
COPY resources/mysql-connector-java-8.0.28.jar /usr/local/hadoop
RUN tar -zxvf /usr/local/hadoop/apache-hive-3.1.3-bin.tar.gz -C /usr/local/hadoop/
RUN mv /usr/local/hadoop/hadoop-* /usr/local/hadoop/hadoop && \
mv /usr/local/hadoop/jdk* /usr/local/hadoop/jdk1.8 && \
mv /usr/local/hadoop/scala* /usr/local/hadoop/scala2.12 && \
mv /usr/local/hadoop/spark* /usr/local/hadoop/spark3.2.1 && \
mv /usr/local/hadoop/mysql-connector-java-8.0.28.jar /usr/local/hadoop/apache-hive-3.1.3-bin/lib/.
# set environment variable
ENV JAVA_HOME=/usr/local/hadoop/jdk1.8
ENV JRE_HOME=$JAVA_HOME/jre
ENV CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
ENV PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
ENV HADOOP_HOME=/usr/local/hadoop/hadoop
ENV PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
ENV SCALA_HOME=/usr/local/hadoop/scala2.12
ENV PATH=$PATH:$SCALA_HOME/bin:$HADOOP_HOME/sbin
ENV SPARK_HOME=/usr/local/hadoop/spark3.2.1
ENV PATH=$PATH:$SPARK_HOME/bin:$HADOOP_HOME/sbin
ENV HIVE_HOME=/usr/local/hadoop/apache-hive-3.1.3-bin
ENV PATH=$PATH:$HIVE_HOME/bin
# ssh without key
RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
RUN mkdir -p ~/hdfs/namenode && \
mkdir -p ~/hdfs/datanode && \
mkdir $HADOOP_HOME/logs && \
mkdir $HADOOP_HOME/tmp
COPY config/* /tmp/
RUN mv /tmp/ssh_config ~/.ssh/config && \
mv /tmp/hadoop-env.sh $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \
mv /tmp/workers $HADOOP_HOME/etc/hadoop/workers && \
mv /tmp/start-hadoop.sh ~/start-hadoop.sh && \
mv /tmp/update-mysql-password.sh ~/update-mysql-password.sh && \
mv /tmp/stop-hadoop.sh ~/stop-hadoop.sh && \
mv /tmp/run-wordcount.sh ~/run-wordcount.sh && \
mv /tmp/hive-site.xml $HIVE_HOME/conf/hive-site.xml
RUN chmod +x ~/start-hadoop.sh && \
chmod +x ~/stop-hadoop.sh && \
chmod +x ~/run-wordcount.sh && \
chmod 700 ~/.ssh && \
chmod 600 ~/.ssh/* && \
chmod +x $HADOOP_HOME/sbin/start-dfs.sh && \
chmod +x $HADOOP_HOME/sbin/start-yarn.sh && \
chmod +x ~/update-mysql-password.sh
RUN sed -i 1a\HDFS_DATANODE_USER=root $HADOOP_HOME/sbin/start-dfs.sh && \
sed -i 2a\HDFS_NAMENODE_USER=root $HADOOP_HOME/sbin/start-dfs.sh && \
sed -i 3a\HDFS_SECONDARYNAMENODE_USER=root $HADOOP_HOME/sbin/start-dfs.sh && \
sed -i 4a\YARN_RESOURCEMANAGER_USER=root $HADOOP_HOME/sbin/start-dfs.sh && \
sed -i 5a\YARN_NODEMANAGER_USER=root $HADOOP_HOME/sbin/start-dfs.sh && \
sed -i 1a\HDFS_DATANODE_USER=root $HADOOP_HOME/sbin/stop-dfs.sh && \
sed -i 2a\HDFS_NAMENODE_USER=root $HADOOP_HOME/sbin/stop-dfs.sh && \
sed -i 3a\HDFS_SECONDARYNAMENODE_USER=root $HADOOP_HOME/sbin/stop-dfs.sh && \
sed -i 4a\YARN_RESOURCEMANAGER_USER=root $HADOOP_HOME/sbin/stop-dfs.sh && \
sed -i 5a\YARN_NODEMANAGER_USER=root $HADOOP_HOME/sbin/stop-dfs.sh && \
sed -i 1a\YARN_RESOURCEMANAGER_USER=root $HADOOP_HOME/sbin/start-yarn.sh && \
sed -i 2a\HADOOP_SECURE_DN_USER=yarn $HADOOP_HOME/sbin/start-yarn.sh && \
sed -i 3a\YARN_NODEMANAGER_USER=root $HADOOP_HOME/sbin/start-yarn.sh && \
sed -i 1a\YARN_RESOURCEMANAGER_USER=root $HADOOP_HOME/sbin/stop-yarn.sh && \
sed -i 2a\HADOOP_SECURE_DN_USER=yarn $HADOOP_HOME/sbin/stop-yarn.sh && \
sed -i 3a\YARN_NODEMANAGER_USER=root $HADOOP_HOME/sbin/stop-yarn.sh
RUN cat /tmp/profile >> /etc/profile && \
rm -rf $HADOOP_HOME/share/doc \
RUN echo "alias python=python3" >> ~/.bashrc
RUN pip install /usr/local/hadoop/pyspark-3.4.1.tar.gz
# format namenode
RUN $HADOOP_HOME/bin/hdfs namenode -format
CMD [ "sh", "-c", "service ssh start; bash"]
docker build -f Dockerfile -t puppets/hadoop:1.1 .
create hadoop network
sudo docker network create --driver=bridge hadoop
start container
点击显示代码
start-container.sh file#!/bin/bash
echo "start hadoop-master container..."
sudo docker run -itd \
--net=hadoop \
-p 9870:9870 \
-p 9860-9866:9860-9866 \
-p 9000:9000 \
-p 4040:4040 \
--name hadoop-master \
--hostname hadoop-master \
puppets/hadoop:1.1
echo "start hadoop-slave1 container..."
sudo docker run -itd \
--net=hadoop \
--name hadoop-slave1 \
--hostname hadoop-slave1 \
puppets/hadoop:1.1
echo "start hadoop-slave2 container..."
sudo docker run -itd \
-p 8088:8088 \
--net=hadoop \
--name hadoop-slave2 \
--hostname hadoop-slave2 \
puppets/hadoop:1.1
sudo ./start-container.sh
output:
start hadoop-master container...
start hadoop-slave1 container...
start hadoop-slave2 container...
Start
docker exec -it hadoop-master bash
./start-hadoop.sh
因为yarn配置在hadoop-slave2节点,所以还需要去hadoop-slave2启动
docker exec -it hadoop-slave2 bash
./start-hadoop.sh
- HDFS UI -> http://localhost:9870/

- SPARK UI -> http://localhost:8088/
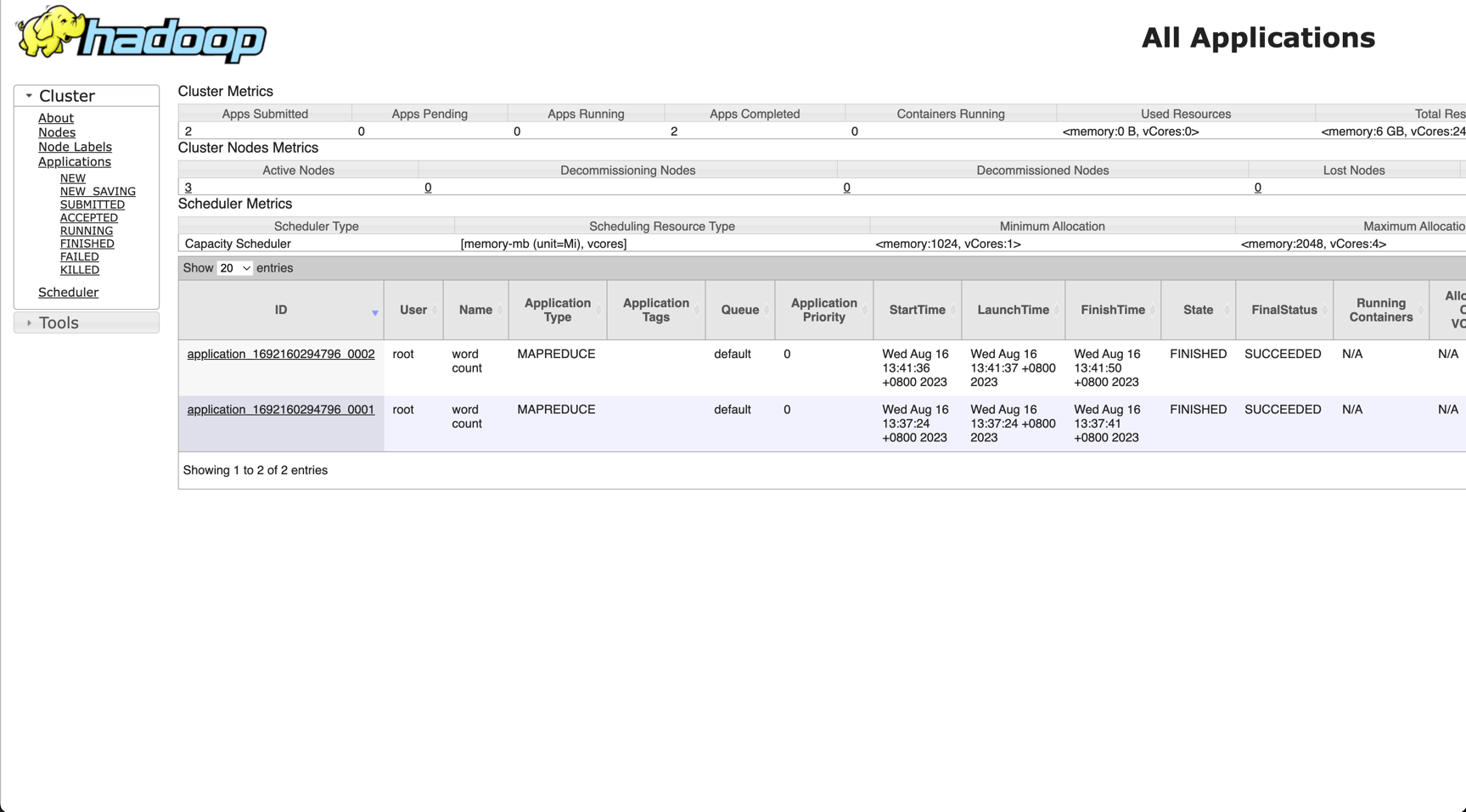
测试
在master节点运行任务
./run-wordcount.sh 3.3.1
output
input file1.txt:
Hello Hadoop
input file2.txt:
Hello Docker
wordcount output:
Docker 1
Hadoop 1
Hello 2